

One of the main challenges for B2B sales teams is to figure out which marketing leads to focus their efforts on. Do you use your gut feeling for that? Some simple if not arbitrary rule that if they’ve downloaded a whitepaper, they’re a hot lead? Hire another SDR for qualification?
We at Outfunnel are in a unique position to find an answer to this question because we connect data from marketing tools like MailChimp and ActiveCampaign with CRMs like Pipedrive and HubSpot, plus we offer our proprietary website visitor tracking software feature. In other words, we can connect marketing touches to deals closed (and lost).
Previously, we’ve analyzed our own data to understand what works in marketing and found out that:
- People who attend a webinar or an onboarding call during our free trial are 3X pipemore likely to start a paid subscription
- Free trial signups that come from paid advertising are half as likely to convert to a paid subscription, compared to those coming from marketplaces channel
It’s useful to know how things have performed historically. We now wanted to peek into the future. Could we make useful predictions on leads’ likeliness to convert based on email engagement and website visits? And does this apply to other companies as well, not just us?
(Spoiler alert: we did, and it does. Keep reading for more details.)
How we applied machine learning to web and email data to generate deal conversion predictions
When you’re talking about web and email engagements, that’s a lot of data. And since we wanted to come up with something that would work universally, we naturally turned to machine learning.
Our dataset included Pipedrive as the CRM tool, Mailchimp as the email marketing tool, and our own web tracking feature as the source of web engagements. All of these tools had activities like web visits, email opens or clicks, main sales activities, and industry tags stored for a period of more than six months. The data was timestamped, so we knew whether certain marketing engagements happened before or after a sales opportunity was opened or closed.
We could have added more sources to the analysis (for example, form fills or Calendly meetings attended) and while this probably would have increased the performance of our models, it would have also reduced the number of leads available for analysis.
Once we knew what we wanted to analyze, our process for developing our predictive lead scoring model was pretty straightforward:
- Prepare our own email, web tracking and CRM data for analysis (ie. data exports from different tools)
- Do thorough exploratory data analysis (EDA) of our own data to get contextual awareness of trends, outliers, and other dataset characteristics as well as discover any inconsistencies in the dataset.
- Build data engineering systems to test the model on the data of 9 other companies (Outfunnel customers): anonymizing datasets, mapping out data schemas, unifying variable names, building pipelines to extract data, and setting up storage solutions.
- Running our predictive scoring model on 9 new datasets to test its broader effectiveness.
- Digesting lessons learned.
Are (marketing) email opens and clicks a strong signal for predicting deal conversion?
We started off by asking a simple question: Is engagement with marketing email campaigns different for won deals and lost deals? As it turns out, yes. There is a clear correlation between opening marketing emails and converting to a “won” deal.
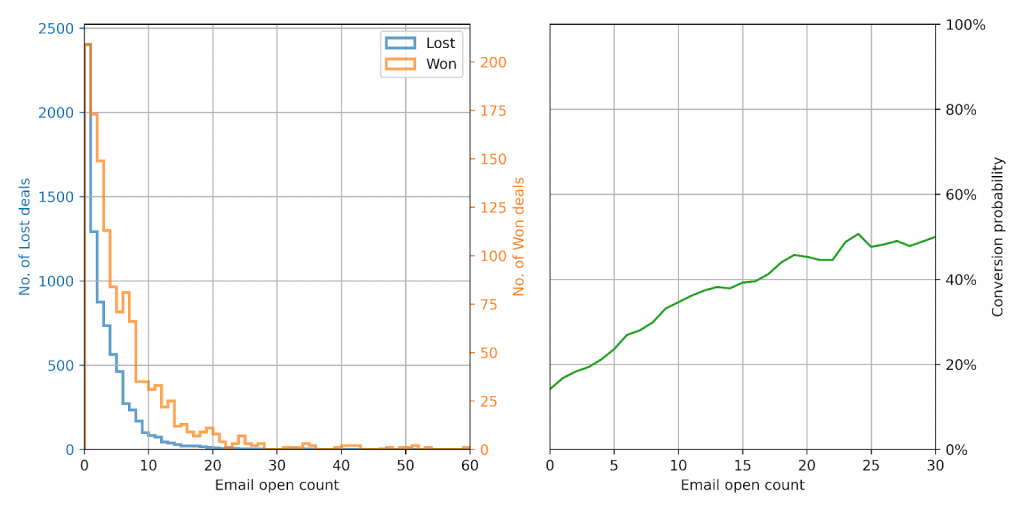
And the more someone opens emails, the more likely they are to buy. A lead who has opened more than 5 emails has nearly twice the chance to convert to a paying customer!
| Number of email opens | Deal conversion probability |
| 0 | 14% |
| 1 | 16.8% |
| 2 | 18.3% |
| 3 | 19.3% |
| 5 | 23.6% |
| 10 | 34.6% |
| 15 | 39.2% |
We then looked at email clicks, and this proved to be an even stronger indicator of a lead’s “warmth”. Even a single email click raised the conversion probability from 14% to 33%. And as with email opens, more clicks correlate with increased conversion to a won opportunity.
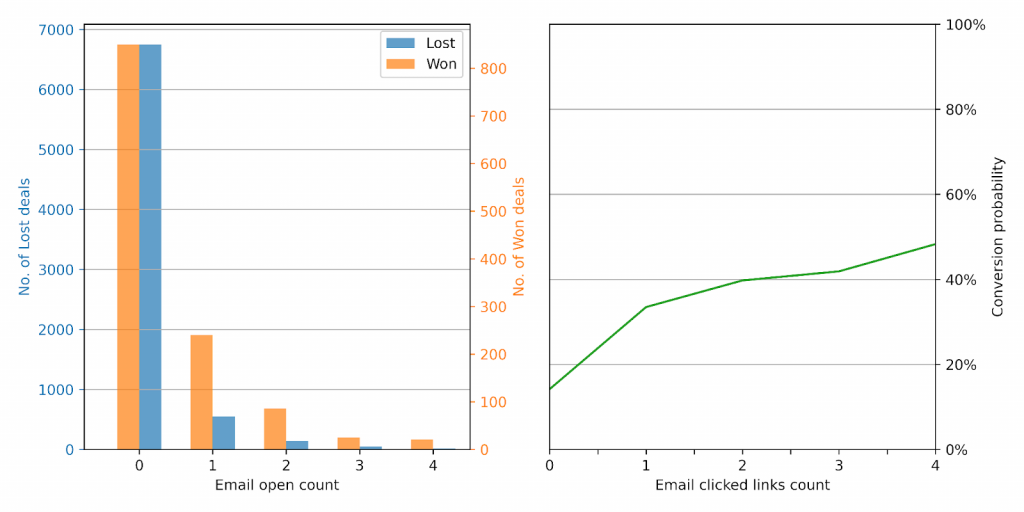
Learning 1: email opens are a pretty good signal for predicting deal conversion, and email clicks are a strong signal
We also had a lot of web visitor data available for analysis, so we kept digging into the data.
Are website visits a strong signal for predicting deal conversion?
We also wanted to see how visiting a company’s website correlates with conversions. The following two heatmaps are comparisons between the two customer classes, specifically their total time spent on our website before and after deal creation in CRM.
Although the two classes were practically indistinguishable before activating the deal/opportunity, it became evident after 5 days that converting customers were exploring the website rather actively whereas the activity of non-converters fell off a cliff.
We’re fairly confident that not all web visits are created equal and that specific pages (eg. product detail pages or pricing pages) are stronger signals for sales opportunities most likely to convert. This wasn’t the main focus of this piece of analysis, so perhaps we’ll dig deeper into this next time.
Learning 2: continuing website visits past opening a deal is a distinct characteristic of converting deals
It’s worth mentioning that we looked at more than the 3 correlations based on EDA covered here (in fact, we set ourselves 15 questions of interest). But these three seemed like the most relevant both from the marketer and data scientist perspectives.
Is the model unique for Outfunnel leads and customers, or does it apply to other companies as well?
After doing exploratory data analysis on our own data, we were able to develop well-performing models that predicted deal conversion probability. We then set out to train models on the data of 9 customers of ours.
One of the main issues encountered was the sheer variability in data across customers – services differ in sales periods’ lengths, the number of people involved, mean activities, and other metrics. This makes generalizing processes difficult, but not impossible.
All of our experimentation was done in a development environment – meaning only developers had to keep things in sync. In a production environment, upkeep and model versioning challenges would have been added on top of everything existing.
As a side note, a separate post will soon follow on our tech blog with more of the technical details.
Learning #3: the model that worked for us worked accurately on roughly half the companies in our (small) sample
Our process saw the training of a total of 434 models for 9 customers. Such a large number of models came from the variety of data sources and algorithms used – 3 data sources, 2 algorithms, and additional derived data engineering features. Ultimately 63 models for 5 different customers had production-grade performance, meaning there was statistical evidence to believe that any of those 63 models could output deal conversion probabilities with tolerable mean error.
What kind of companies can benefit from analysis and machine learning models like this?
Quite early into the process, we asked ourselves: “What is the minimum number of closed deals a customer needs to have to train a decently performing model?” From our machine learning process, we concluded the critical minimum limit to be ca. 100 closed deals/opportunities.
We were also interested in whether the win-loss ratio of deals could be an indicator of which of our customers we could offer this service to. When we looked at our well-performing models, the win-loss ratios were ranging too dramatically to make any conclusions. If we analyze more customers’ data, perhaps we could look at the win-loss ratio in combination with a number of deals, however, at the current state, it proved not to be a useful metric.
Previously we mentioned that our source datasets came from CRM, email, and website visitor tracking tools. Does a business need to be using all of these tools to be able to use performant deal conversion predicting models? A business can use all three tools or only one of the aforementioned tools. Our analysis included training models with a variety of source datasets:
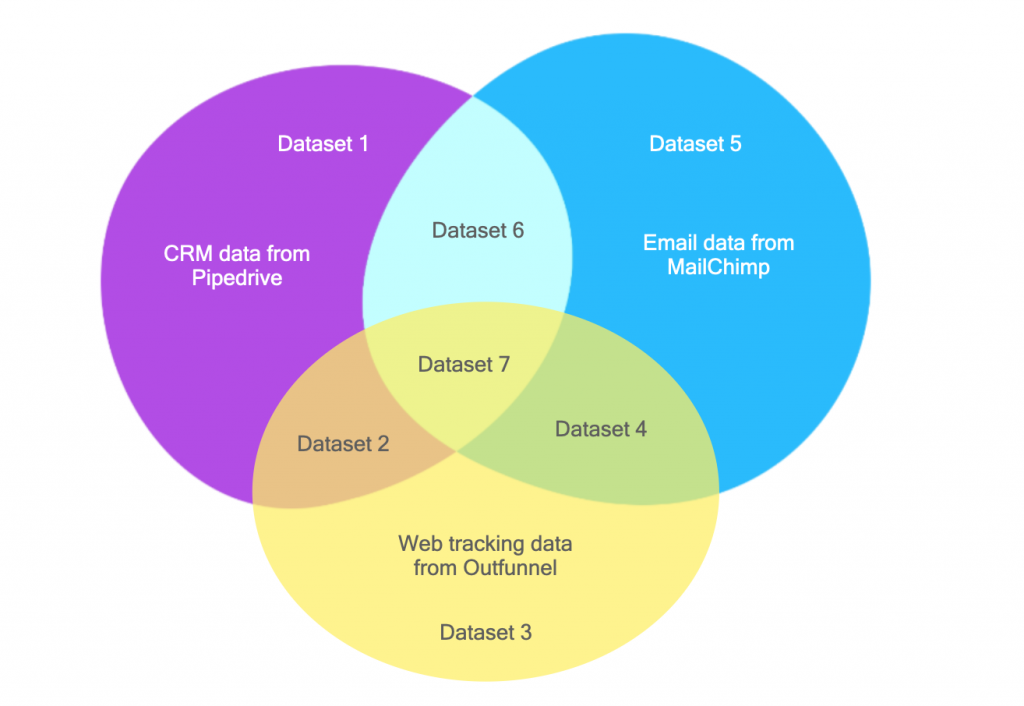
For some businesses, we were able to train performant models using just a single tool, but for others, multiple tools were needed.
Ultimately whether a business can performantly predict its lead closing probability depends on multiple factors: data quantity, data quality, source data characteristics, and the amount of work put into achieving results.
Unsurprisingly, the more sales and marketing data you have (from different sources(, the higher the chances of you being able to train a model for your business.
A useful sidenote – the false negative and false positive dilemma (and how it manifests in sales and marketing)
You can never build the perfect ML model to correctly predict every outcome. A question one has to ask when building a classifier model is whether to prefer false positives or false negatives. What does this mean (in the context of sales and marketing)?
Let’s say you have 1000 potential customers, and 10 will surely start paying. Now if your model A predicts that 1000 out of the 1000 will not become customers, the model is 99.9% accurate but has a 0% detection rate for positive matches. Model A is producing many false negatives.
But if your model B predicts that 50 customers will convert and 950 will not convert, then it is less accurate than model A but a lot more useful since it has some detection capability for positive matches. It produces many false positives.
Another way to think about false positives is that false positives are cases when the model predicted a deal to convert, whereas the deal actually did not convert. At the same time, a false negative is a case where the model predicted the deal to not convert but it actually converted.
This false negative / false positive focus dilemma is part of the problem statement. If you have too many leads and the sales team is overburdened, then your model should be lower on false positives not to waste any more of your precious time on dead ends.
But if you have too few leads and a large enough sales team to continuously engage them, then you would benefit more from a model which is lower on false negatives.
So, how to approach predicting the closing probability for leads
I realize very few of our customers have the technical chops to train machine learning algorithms on their data to draw useful conclusions.
But almost all businesses can be smarter about finding the best-converting leads (and not wasting time on leads that won’t convert no matter what).
The first thing any business can do is to pay attention to web visits and opens and clicks of marketing emails, and make sure this information is not locked away in the marketing automation platform but easily available in your CRM.
If this sounds relevant, our app connector can sync email engagement from tools like MailChimp, ActiveCampaign, Sendinblue and HubSpot Marketing Hub.
If you think website visits are more relevant for your business, we offer website tracking too.
Secondly, if you’re working with a large volume of leads and lots of sales reps, it may be impractical to follow up on each website visit and email activities like clicks. You may want to feed all those events into a lead-scoring solution, and only work with leads where the score is higher than X. In other words, X would be the score your sales and marketing teams agree to be high enough to be considered a Marketing Qualified Lead.

We’re big fans of lead scoring and we gladly offer this to anyone using Pipedrive, HubSpot, Copper, or Salesforce as their CRM.
Last but not least, it’s 2022 and it’s relatively easy for almost anyone to use the real thing, to put machine learning to work on sales and marketing data.
There are service providers like Breadcrumbs and MadKudu that are happy to put your data to work. As you hopefully saw, we at Outfunnel have also taken first steps in predictive lead scoring and we’d be happy to work with you as a (paid) pilot customer if this sounds interesting. Simply sign up here for more details.
This post was co-written with Sebastian Pikand, the machine learning consultant that helped us run this analysis.


